Finding the n’th Aggregate Value from Every Group in AWS Athena/Presto #
Co-Author: Palash Nimodia
Date: June 2, 2022
Medium Link: https://medium.com/selectfrom/finding-the-nth-aggregate-value-from-every-group-in-aws-athena-presto-1da505310901
Prerequisite: #
Before going ahead, a quick read for those who don’t know what AWS Athena and Presto are.
- AWS Athena:
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is easy to use, fast, scalable and serverless, so there is no infrastructure to manage, and we pay only for the queries that we run. We also don’t have to pay for failed queries. This makes it easy for anyone with SQL skills to quickly analyze large-scale datasets.
- Presto:
Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes. AWS Athena uses Presto internally as its query engine.
Introduction: #
Continuing on with our main focus, today we will discuss finding the nth aggregate value from every group in AWS Athena/Presto).
Let’s take an example: finding some aggregate value from every group in SQL is possible and its solutions are quite easily available. Across the few solutions that I went through, two things were common:
- It always referred to the 2nd highest/lowest.
- Most of the solutions used SQL variables and inner join.
Now imagine a scenario where you are required to find the 5th…. 6th…. nth largest/smallest/aggregate value from every group where data size is HUGE (in TB’s) and you are restricted from using SQL variables.
In such scenarios, due to the sheer scale, inner-join will be a very heavy operation and hence its best to avoid it. Another restriction being the use of variables in AWS Athena. Since AWS Athena is used for data analytics and not transactional databases, the use of variables is not supported as of now.
So after the above discussion, is there any other way ??? …… Yes, there is. Let’s have a quick look at the dummy data-set first and then move onto our solution.
The dummy data-set has 1,000 rows and 4 columns. The “id” column has 10 unique values of type varchar. The “date” column is of type date-type. The “class-type” column is of data-type varchar containing values namely: “extra”, “vip”, “normal”. The “class-marks” column contains integers ranging between 0 and 100.
This is how the dummy data-set looks
Data Download: The dummy data-set is very small in size and it is uploaded on GitHub — augmented-data.csv
Let’s define a question now:
Question 1: #
For every ID, find the 5th highest scorer from every unique “class-type”.
Pre-work: The above data-set is uploaded on AWS S3 and crawled using AWS Glue. This crawled table is now easily accessible using AWS Athena.
Solution: #
Let’s divide the solution into 3 parts, hence containing 3 nested queries. (The entire query is attached at part 3)
Part 1: #
— — — — — —
As we are required to compute the highest scorer, we will need to sort the table based on marks in descending order. The query to perform that will be as follows:
— — — — — —
Query1: #
WITH "sorted_marks_table" AS(
SELECT *
FROM "augmented_data"
ORDER BY "augmented_data"."class-marks" DESC
)
SELECT *
FROM "sorted_marks_table";Query1 Output: #
augmented_data table in sorted order
Part2: #
— — — — — —
In the next part, let’s work on grouping. We need to compute the highest scorer for every ID, hence we will need to group by on the ID column. In this sub-query, we will create a mapping (you can imagine a hash-map/dictionary) between “class-type” and “class-marks” column and group by on “id” column. It will be such that for every unique id the map key will be unique class type and value will be a list consisting of all the marks associated with that id and class name.
Please observe the output image, since we had already sorted the table based on marks in the earlier sub-query, the value list is also sorted in the highest to lowest marks(descending).
— — — — — —
Query2 (In combination with Query1): #
WITH "sorted_marks_table" AS(
SELECT *
FROM "augmented_data"
ORDER BY "augmented_data"."class-marks" DESC
),
"mapping_table" AS (
SELECT id,
multimap_agg("class-type", "class-marks") AS "mapping_col"
FROM "sorted_marks_table"
GROUP BY "id"
)
SELECT *
FROM "mapping_table";Query2 Output: #
Table grouped on “id” column such that all the marks are associated with the unique class-types.

Part3 (Final): #
— — — — — —
Now, in the final part we just need to display the required results from our map. As we have all the marks in sorted order for every class type and we need the 5th highest scorer, we will select the 5th place value from every key of the map.
One caveat of this solution is that we need to know the unique keys beforehand and need to explicitly specify the key-name. But there is a reason behind this, unlike some programming languages like Python or Java, we are using a form of SQL and we need to know the schema of the Database before-hand.
— — — — — —
Query3: #
WITH "sorted_marks_table" AS(
SELECT *
FROM "augmented_data"
ORDER BY "augmented_data"."class-marks" DESC
),
"mapping_table" AS (
SELECT id,
multimap_agg("class-type", "class-marks") AS "mapping_col"
FROM "sorted_marks_table"
GROUP BY "id"
)
SELECT "id",
mapping_col [ 'normal' ] [ 5 ] as "normal_max_5th",
mapping_col [ 'vip' ] [ 5 ] as "vip_max_5th",
mapping_col [ 'extra' ] [ 5 ] as "extra_max_5th"
FROM "mapping_table";Query3 Output: #
Final output containing the 5th highest marks from every‘ class-type’ for every ‘id’
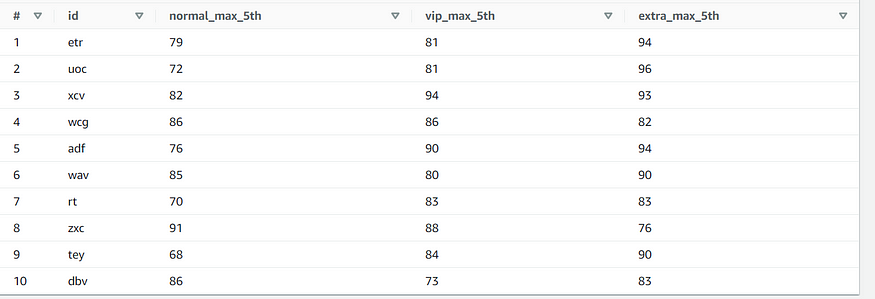
That’s it! We are done and dusted. We have found the 5th largest scorer for every id for every “class-type”.
— — — — — — — — — — — — — — — — — — — — — — — — — —
Are we not done? Why is this blog not ending here?
Let’s try computing another very similar question.
Question2: #
For every ID, find the 3rd lowest scorer from every unique “class-type” #
Solution: #
WITH "sorted_marks_table" AS(
SELECT *
FROM "augmented_data"
ORDER BY "augmented_data"."class-marks"
),
"mapping_table" AS (
SELECT id,
multimap_agg("class-type", "class-marks") AS "mapping_col"
FROM "sorted_marks_table"
GROUP BY "id"
)
SELECT "id",
mapping_col [ 'normal' ] [ 3 ] as "normal_max_3rd",
mapping_col [ 'vip' ] [ 3 ] as "vip_max_3rd",
mapping_col [ 'extra' ] [ 3 ] as "extra_max_3rd"
FROM "mapping_table";Question2 Output: #
Final output containing the 3rd lowest marks from every‘ class-type’ for every ‘id’
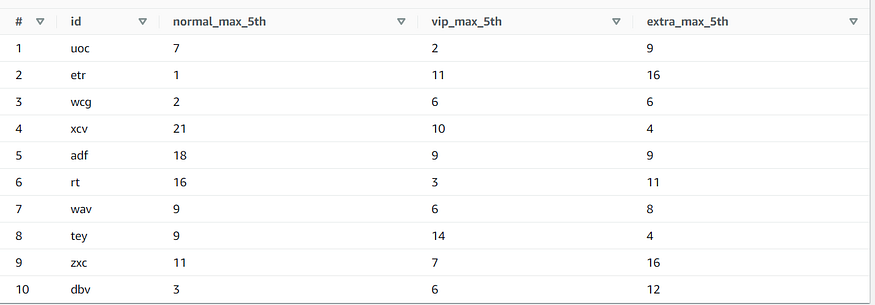
So what did we change:
We sorted the table in ascending order in the first part of the query and selected the 3rd element this time.
That’s it! GG! 👏
I hope you found this article instructional and informative. If you have any feedback or queries, please let me know in the comments below.
| Tags | AWS, SQL, Presto, Data Science, Data |
|---|---|