Benchmarking Inference with Torchserve #
| Last Edited | 05/01/2024 |
Pytorch default - g4dn.xlarge #
Notes: #
-
Instance Type: ml.g4dn.xlarge
- GPU: Nvidia T4
- vCPU no: 4
- CPU memory: 16 GB
- GPU memory: 16 GB
-
Max RPS achieved: 32
- With various different configuration ranging from min/max worker = 1 to 4 and batch-size 4 to 32, the max RPS possible was only 32.
- Locust Configuration: Max Users: 200, Spawn Rate: 10
- With various different configuration ranging from min/max worker = 1 to 4 and batch-size 4 to 32, the max RPS possible was only 32.
-
Max Response time at 95th percentile: ~5-6 sec
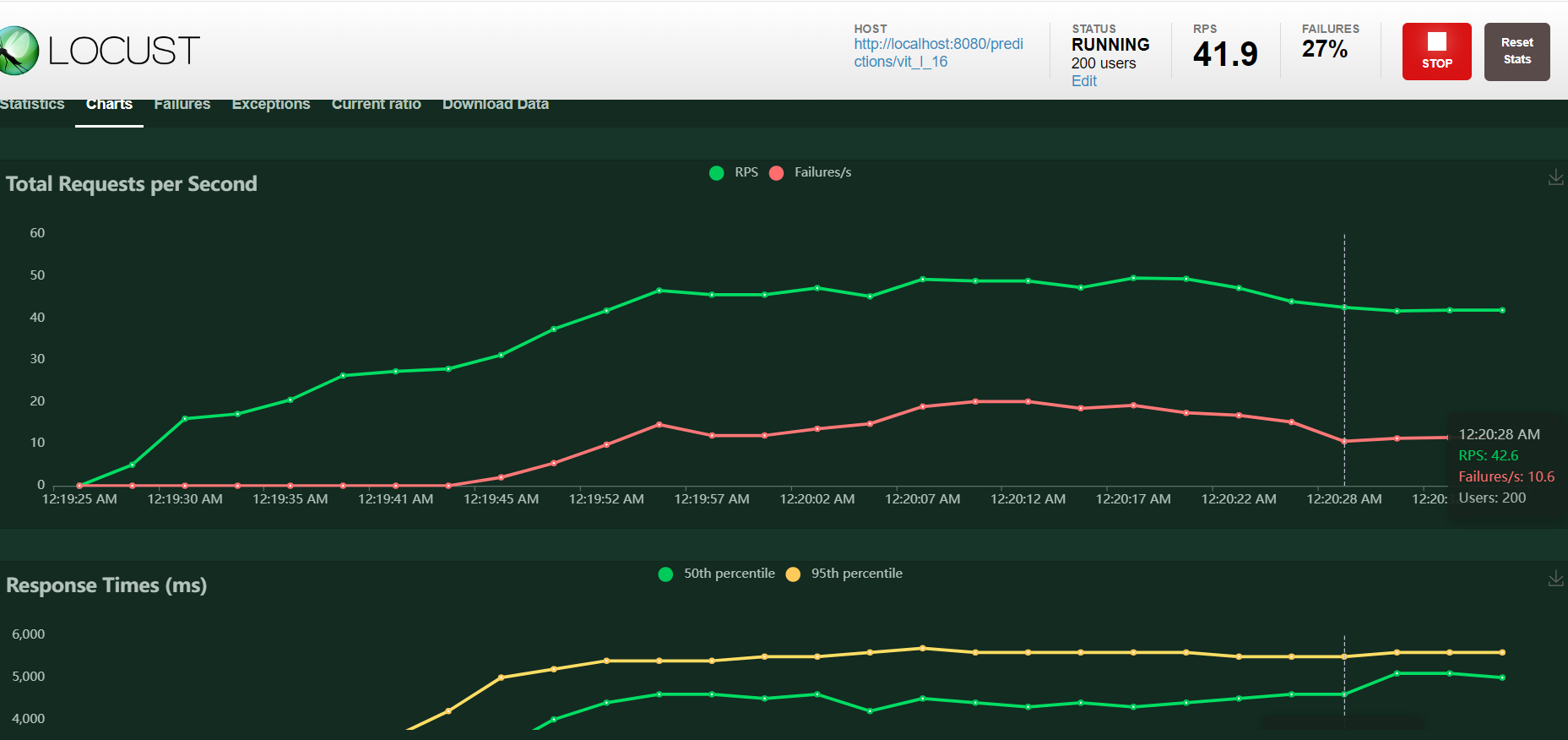
Configuration: #
enable_envvars_config=true
load_models=all
model_store=./model_store
models={\
"vit_l_16": {\
"1.0": {\
"defaultVersion": true,\
"marName": "vit_l_16.mar",\
"minWorkers": 4,\
"maxWorkers": 4,\
"batchSize": 16,\
"maxBatchDelay": 50\
}\
}\
}
Pytorch default - g4dn.2xlarge #
Notes: #
-
Instance Type: ml.g4dn.2xlarge
- GPU: Nvidia T4
- vCPU no: 8
- CPU memory: 32 GB
- GPU memory: 16 GB
-
Max RPS achieved: 32
- With various different configuration ranging from min/max worker = 1 to 4 and batch-size 4 to 64, the max RPS possible was only around 32.
- Locust Configuration: Max Users: 200, Spawn Rate: 10
- With various different configuration ranging from min/max worker = 1 to 4 and batch-size 4 to 64, the max RPS possible was only around 32.
-
Max Response time at 95th percentile: ~5-6 sec
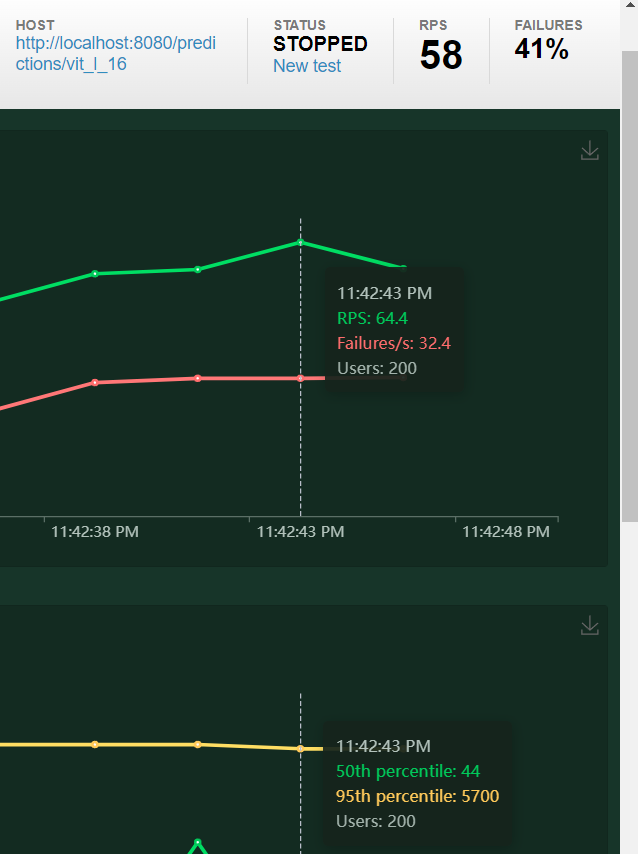
- It can be noted that the GPU utilization is at 100% but the gpu memory is underutilized and the vCPU’s are also unutilized
- Never the less, with any change in configuration in number-of-model-workers or batch-size or delay, the results and utilization numbers does not change.
Configuration: #
enable_envvars_config=true
load_models=all
model_store=./model_store
models={\
"vit_l_16": {\
"1.0": {\
"defaultVersion": true,\
"marName": "vit_l_16.mar",\
"minWorkers": 1,\
"maxWorkers": 1,\
"batchSize": 64,\
"maxBatchDelay": 200,\
"responseTimeout": 240\
}\
}\
}
Does Dynamic Batching Really Help (PS: It dooes) #
Instance used: (G4dn.2xlarge)
- I can imagine 2 scenarioes,
- where workers is set to 1 and batch size 1
- where workers > 1 (atleast 4) and batch-size 1
Batch-size 1 and workers 1: #
-
Instance Type: ml.g4dn.2xlarge
- GPU: Nvidia T4
- vCPU no: 8
- CPU memory: 32 GB
- GPU memory: 16 GB
-
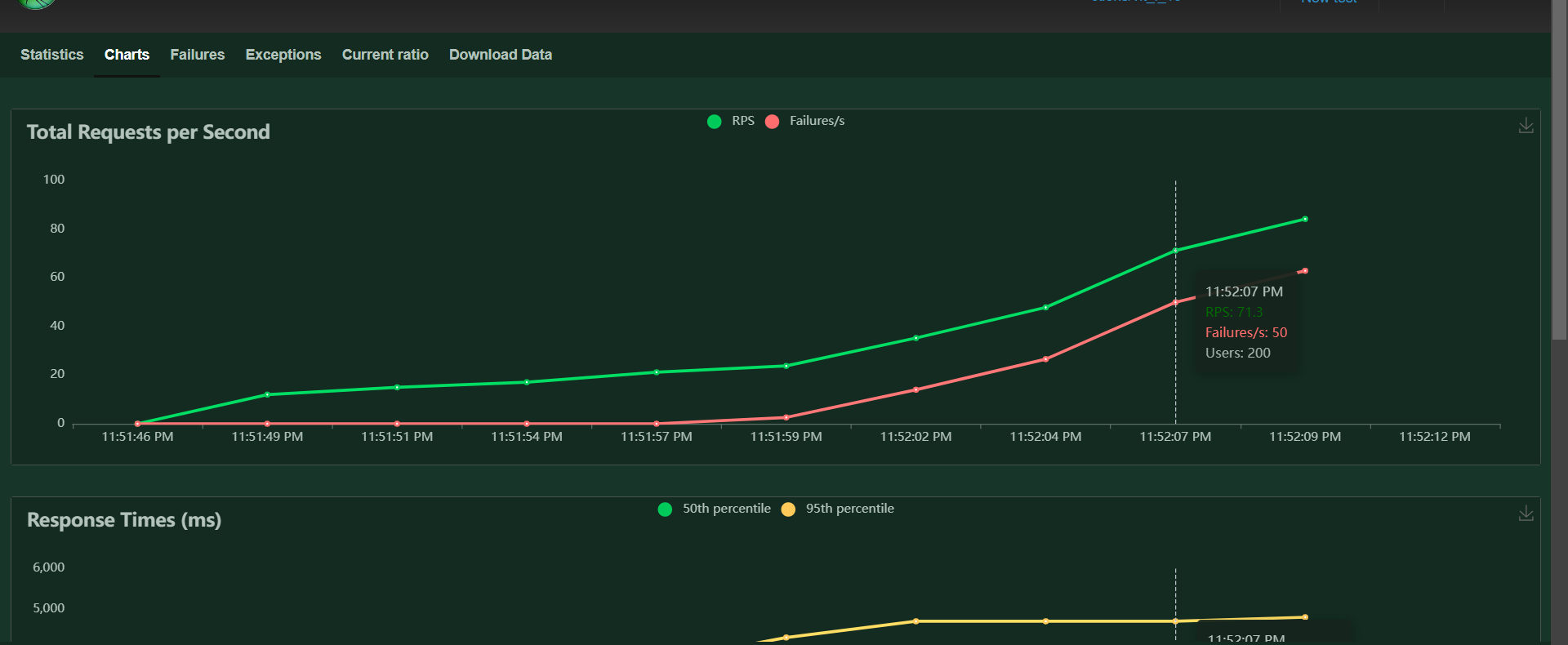
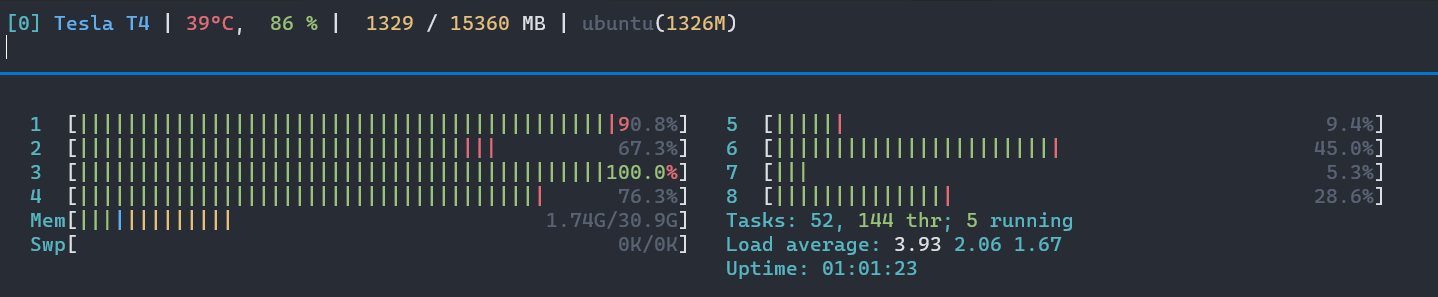
Max RPS achieved: 21
- min/max workers = 1 and batch-size = 1, the max RPS possible was only around 21.
- Locust Configuration: Max Users: 200, Spawn Rate: 10
- min/max workers = 1 and batch-size = 1, the max RPS possible was only around 21.
-
Max Response time at 95th percentile: ~5 sec (close to 4.9 sec)
- Its a bit less than dynamic batching as torchserve does not have to wait for extra time for creation of batches
- Note: The GPU utilization is also not full
Configuration: #
enable_envvars_config=true
load_models=all
model_store=./model_store
models={\
"vit_l_16": {\
"1.0": {\
"defaultVersion": true,\
"marName": "vit_l_16.mar",\
"minWorkers": 1,\
"maxWorkers": 1,\
"batchSize": 1,\
"maxBatchDelay": 200,\
"responseTimeout": 240\
}\
}\
}
Batch-size 1 and workers 4: #
-
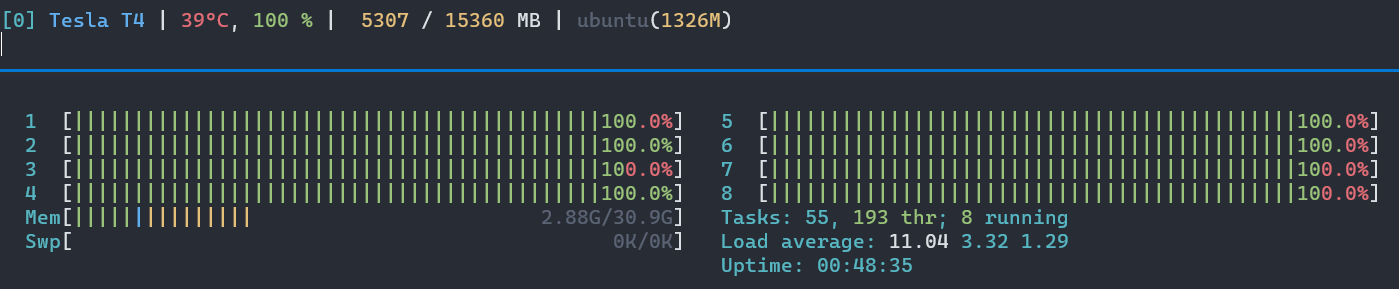
Note: For some reason, with workers 4, the GPU utilization is 100 but the RPS is still the same
-
Instance Type: ml.g4dn.2xlarge
- GPU: Nvidia T4
- vCPU no: 8
- CPU memory: 32 GB
- GPU memory: 16 GB
-
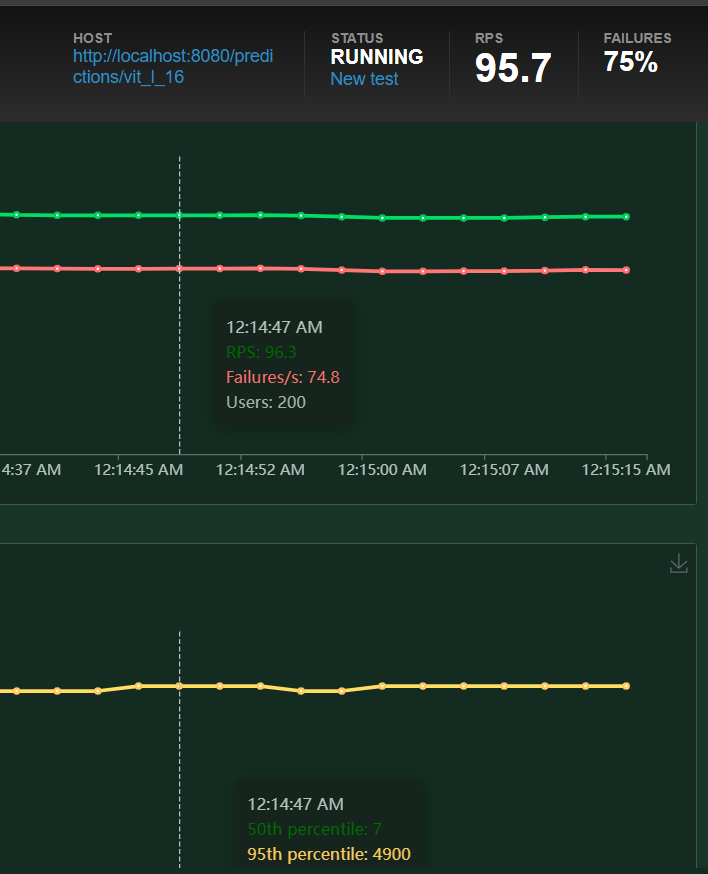
Max RPS achieved: 21
- min/max workers = 4 and batch-size = 1, the max RPS possible was only around 21.
- Locust Configuration: Max Users: 200, Spawn Rate: 10
- min/max workers = 4 and batch-size = 1, the max RPS possible was only around 21.
-
Max Response time at 95th percentile: ~5 sec (close to 4.9 sec)
- Its a bit less than dynamic batching as torchserve does not have to wait for extra time for creation of batches
Configuration: #
enable_envvars_config=true
load_models=all
model_store=./model_store
models={\
"vit_l_16": {\
"1.0": {\
"defaultVersion": true,\
"marName": "vit_l_16.mar",\
"minWorkers": 1,\
"maxWorkers": 1,\
"batchSize": 1,\
"maxBatchDelay": 200,\
"responseTimeout": 240\
}\
}\
}